Optical character recognition, often abbreviated as OCR, plays an enormous part in the text recognition software many of us rely on today through Adobe Acrobat, Google Drive, and the like. While most would assume that the ability to recognize and translate an image to text would be a modern-day invention based on some contemporary algorithm, the truth is that OCR software and picture-to-text technology have been around since at least the late 1920s. The man responsible for one of the earliest OCR innovations? An Austrian engineer named Gustav Tauschek. He’s the one who patented an optical character recognition device in Germany in 1929 and again in the United States in 1935.
But how did Gustav Tauschek come up with such a novel idea for software? And how did it work with such archaic software at the time? Not to mention, what is the historical significance of Tauschek’s text recognition software? Thankfully, each of these questions has an answer. Read on to learn more about Gustav Tauschek and his OCR invention.
Quick Facts
- Created
- 1929
- Creator (person)
- Gustav Tauschek
- Original Use
- Text recognition
- Cost
- N/A

Key Points about Optical Character Recognition (OCR)
- The earliest forms of OCR image-to-text devices were conceived in the late 1800s for use with the blind. Inventors hoped that their rudimentary picture-to-text software could help the blind to read.
- In the 1970s, American inventor Ray Kurzweil created Kurzweil Computer Products Inc. — a company that took serious inspiration from Gustav Tauschek’s device in the creation of its omni-font OCR software. Remarkably, Ray Kurzweil’s algorithm was capable of recognizing practically any text font.
- In addition to his groundbreaking image-to-text invention, Gustav Tauschek developed 169 patents and sold them all to IBM. Given a five-year contract by the software giant, Tauschek used OCR technology to develop a punchcard-based accounting system and several other OCR-reliant, punchcard-based machines.
Optical Character Recognition (OCR) History
Viennese engineer Gustav Tauschek was something of a self-taught genius during his time in the early 20th century. With over 200 patents to his name — including the aforementioned 169 sold to IBM — Tauschek was undoubtedly a software mastermind capable of creations far ahead of what was being invented by his contemporaries at the time. Throughout his career, he worked for both IBM and the German arms and automotive manufacturing company Rheinische Metallwaren- und Maschinenfabrik (known as Rheinmetall today).
Tauschek’s work with optical character recognition began with the mission to create software capable of transforming pictures to text with accuracy and efficiency. His main use for this proprietary technology was in his punchcard-based calculating machines. From there, Tauschek invented the Reading Machine of Tauschek: a mechanical device that could read characters and numerals on an image and transform them into printed characters and numbers on a piece of paper.
Many before Tauschek’s time — such as American inventor Charles R. Carey — had come up with similar, earlier forms of the OCR, but Tauschek was the first to take it off the page and turn it into a real-world device with his Reading Machine.
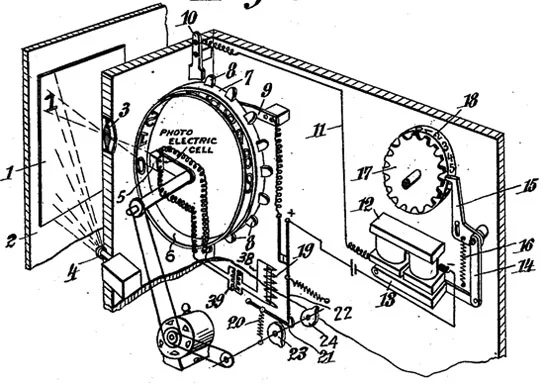
Optical Character Recognition (OCR): How It Worked
Gustav Tauschek’s Reading Machine was a mechanical device that used a template that matched with a photoelectric photodetector. As a picture with text passed in front of the reading machine’s eye-like window, the comparison device — a disk with holes in the shape of letters and numbers — rotated in front of the window in search of a fit. When text on the image matched up with one of the letter-shaped holes on the comparison device, the machine rotated the printing drum to the corresponding letter. Then, the letter was printed onto a piece of paper.
From this time in 1929 through to the modern-day, the OCR device went through all sorts of different changes to meet all sorts of different needs (which will be touched on below). At the end of the day, though, the same basic concept remains integral to the development of OCR devices: the transformation of text on an image into machine-encoded text.
Optical Character Recognition (OCR): Historical Significance
After Tauschek’s novel invention, many other inventors and engineers took his ideas and extrapolated them in all sorts of different notable directions. This is, without question, the most historically significant thing about the OCR: the sheer number of different uses for Tauschek’s creation that came in the decades after.
In 1931, OCR technology was used in the creation of a text-to-telegraph device. From there, in 1951, this tech transformed into a text-to-Morse Code device. Then, in 1966, the technology became capable of reading handwriting and transforming it into text. In 1978, Ray Kurzweil’s Omni-font OCR came into existence. Then, in the ‘80s, OCR technology became an integral part of barcode scanners in retail stores and Xerox machines in offices and schools. Today, Google Drive and Adobe Acrobat offer free, online versions of OCR software capable of working in over 200 different languages with accuracy and clarity.
Clearly, from Gustav Tauschek to Ray Kurzweil to Google Drive and everyone in between, the OCR algorithm has major historical significance that continues to be innovated and improved still today.

